Everything—all the instructions, operands and addressing modes—is encoded in binary code. In Reduced Instruction Set Computers (RISCs), every instruction should be exactly the same length in machine code, typically 32 bits. This makes looking ahead at upcoming instructions simpler. In the 68000, instructions are of variable length, composed of a one-word operation word and zero or more extension words.
You need to understand the scheme by which instructions are encoded to understand how to select the fastest or most compact instructions. In this lecture we will look at encoding schemes and approximate speed calculations.
Learning Outcomes:
On completion of this lecture, you will be able to:
- Discuss the stages of the fletch-decode-execute cycle;
- Describe the internal organisation of the CPU;
- Describe the makeup of a 68000 instruction;
- Discuss instructions execution time calculation;
18.1 Instruction Execution
The Von Newman architecture model of a computer states that the CPU is responsible for reading instructions from the memory system and executing them. The CPU operates by following the so called fletch-decode-execute cycle:
- Fetch the operation word
- Decode the operation word*
- Fetch the rest of the instruction—the extension words
- Fetch any off-processor operands
- Perform the operation itself.
The cycle repeats after the CPU takes the time to put away results to off-processor locations. Fig. 19.1 illustrates the CPU’s functional units that make possible the instruction execution cycle. The CPU registers and units involved in the process are:
MAR The Memory Address Register holds the address of the next location in the store to be accessed. The contents of the MAR point to the location of information in memory. For example, if the MAR contains the value $4000, the CPU is going to access address number $4000 in the memory.
PC The Program Counter contains the address of the next instruction to be executed.
MBR The Memory Buffer Register holds the data just read from the main store, or data to be written into the main store. All information that flows into or out of memory passes through the MBR.
IR The Instruction Register holds the most recently read instruction from the main store.
ALU The Arithmetic and Logic Unit calculates a function of one or two inputs. The actual function performed by the ALU is determined by the bit pattern of the instruction in the IR.
CU The Control Unit interprets the instruction in the IR. That is, the CU is responsible for converting the bit pattern of an instruction into the sequence of actions necessary to execute the instruction.
D0 Data Register D0 can be used as an accumulator to hold temporary data in the CPU during arithmetic and logical operations.
CCR The Condition Code Register is used to implement conditional branches.
Fig. 18.1: Structure of a typical CPU
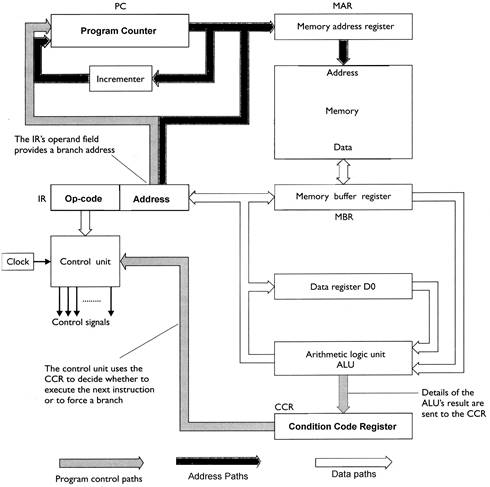
- Fetching an instruction begins with the contents of the Program Counter being moved to the Memory Address Register ([MAR] <- [PC]). The MAR is now pointing at the next instruction to be executed. Once the PC has done its job, it is automatically incremented to point the next instruction in sequence. After the increment, the PC points at the next instruction while the current instruction is being executed.
- The next step is to read the contents of the memory location pointed at by the MAR. The data read from memory is first deposited in a temporary holding register, the Memory Buffer Register ([MBR]<-[MAR]).
- In the final step of the fletch cycle the contents of the MBR are copied the Instruction Register ([IR]<-[MBR]). The IR holds the instruction while it is decoded by the Control Unit. One field of the IR contains the operation code (op-code) that tells the CPU what operation is to be carried out. A second field, called the operand field, contains the address of the data to be used by the instruction.
- The fletch phase is followed by an execution phase in which the Control Unit generates all signals necessary to execute the instruction. The CU controls all parts of the CPU including all programmable registers and the Arithmetic and Logic Unit.
- A path between the CCR and the CU is used by the CU to decide whether to continue with the next instruction in series, or to jump to the address field specified by the branch field of a conditional instruction.
18.2 Makeup a 68000 instruction
|
|
|
|
|
op-word |
zero or more extension words (max: four) |
|
|
|
|
|
The operation word contains:
- the operation and size, e.g. MOVE.W, MULU, BNE
- the types of addressing mode(s) used to reference the operand(s)
Exception: in a quick immediate mode, the op-word also indicates the destination register.
Extension words are used to hold the components of operands that won’t fit into the operation word, which include:
- Addresses -- for absolute memory long and short;
- Immediate values -- byte, word, longword (not Quick Immediate -- they are stored in the operation word);
- Offsets -- for the addressing mode ‘Address Register Indirect with Offset’;
- Index Register and Offset -- for the addressing mode ‘Address Register Indirect with Index Register and Offset.
MODE |
SIZE |
EXTENSION WORDS |
Immediate |
byte |
|
word |
|
longword |
|
Absolute |
short |
|
long |
|
Address Register Indirect (and PC-Relative) |
With [16-bit signed offset] |
|
With index register and [8-bit signed offset] |
|
All Other Modes |
__ |
0 word |
18.3 Instruction Execution Timing
You can get a good estimate of an instruction execution time by calculating the number of bus transactions required to:
- Fetch the instruction and its extension words;
- Fetch the off-processor operands;
- Put away the off-processor results.
The bus can transfer one word (or part) in each transaction (a bus cycle). On the 8MHz 68000, a transaction takes 0.5μS.
These estimates assume that bus transactions always take a fixed amount of time. However:
- an instruction cache could shorten bus transactions fetching an instruction;
- a data cache could do the same for fetching or putting away data.
So, these would be worst-case estimates for a machine with a cache. But the 68000 doesn’t have a cache. The 68000 has a one-instruction look-ahead facility:
- While the current instruction is being executed, the operation word of the next one is being fetched.
- Any operation that takes less than one bus transaction is ‘invisible’ and doesn’t add any overall time to instruction execution (as per our assumption).
- A branch requires the pre-fetched operation word to be discarded—penalty: one half of a bus transaction.
- Multiply and divide instructions take way in excess on one transaction.
18.4 Conclusion
A computer operates following a fletch-decode-execute cycle in which the CPU reads an instruction from memory and then decodes and executes it.
Instructions are made of two parts: the operation code and the address of the operands. The op-code is composed of an op-word associated with extension words.
Knowledge of instruction timing allows the programmer determine the best instructions and addressing modes to use and the duration a sequence of instructions will take to execute
REFERENCES
- Clements; The CPU and its Memory, In: 68000 Family Assembly Language; pp.45-59; PWS Publishing Company; 1994.
- Dr. Mike Brady, Microprocessor Systems 1, dept of Computer Science, Trinity College Dublin: http://www.tcd.ie/Engineering/Courses/BAI/JS_Subjects/3D1/.
- Look on the Web. Look at http://www.mee.tcd.ie/~assambc/3D1.
Course Topics
- Review of binary and hexadecimal arithmetic
Binary |
decimal |
Hexadecimal |
100111 |
39 |
27 |
10010011 |
147 |
93 |
101101011111 |
2911 |
B5F |
1000101111010001 |
35793 |
8BD1 |
101101 |
45 |
2D |
1011101110 |
750 |
2EE |
001011010101000001 |
46401 |
B541 |
11010010111010111111 |
863935 |
D2EBF |
Von Neumann design principle of a computer separates special functions into special purpose devices: The CPU (Central Processing Unit) is the unit specialised in executing instructions, Memory stores data and programs in binary and Peripheral interfaces mediate between the outside world and the interior world of the computer. Information is moved across the different units via a bus.
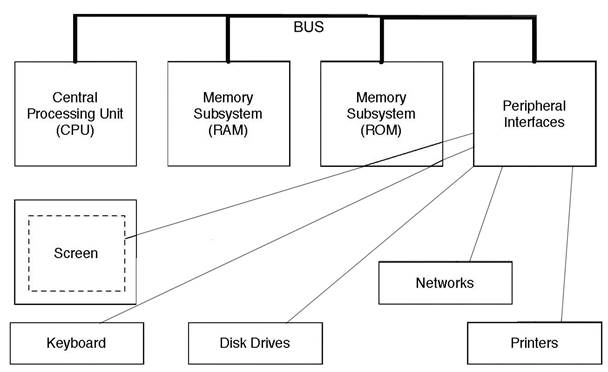
Representation of the Von Neumann machine architecture
The programmer’s model of the MC68000
The 68000 programmer’s model defines the structure and functionality of the processor registers that can be directly addressed by a program; it consists of:
- eight general-purpose 32-bit data registers D0 to D7: On-chip registers can be accessed more rapidly than locations in main memory store. Therefore data registers are used to store frequently used data in order to speed up the processing. Instructions can be specified to operate on 8-, 16-, or 32-bit pieces of data in the data registers.
- eight 32-bit address registers A0 to A7 (and A7’) that hold the location of variables in memory: Only word (16-bit) and long-word (-32) bit operations are valid. Word results loaded into an address register are extended to 32 bits. Registers A0 through A6 perform identical functions. Registers A7 and A7’ are used as stack pointers: A7 is operational at the user state whist A7’ is reserved to the supervisor state.
- one 32-bit Program Counter (PC): register that holds the memory address of the next instruction to be executed. Address values in the PC use the 24 lower register bits, thus a directly addressable 16MByte area is generated. Memory is byte addressable.
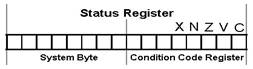
- one 16-bit Status Register (SR): The eight most significant bits are called the system byte and control the MC68000’s operating system. The least significant eight bits of the SR constitute the condition code register (CCR) and indicates the outcome of arithmetic and logical operations.
- Data representation: integers, characters, signed representations, arrays
Size |
Representation |
Range |
Byte |
Unsigned Binary |
 0 255 (0 to 28-1) 0 255 (0 to 28-1)
|
Byte |
Signed Binary |
 -128 +127 (-27 to 27-1) -128 +127 (-27 to 27-1)
|
Word |
Unsigned Binary |
 0 65535 (0 to 216-1) 0 65535 (0 to 216-1)
|
Word |
Signed Binary |
 -32768 32767 (-215 to 215-1) -32768 32767 (-215 to 215-1)
|
Longword |
Unsigned Binary |
 0 4,294,967,295 (0 to 232-1) 0 4,294,967,295 (0 to 232-1)
|
Longword |
Signed Binary |
 -2,147,483,648 +2,147,483,647 (-231 to 231-1) -2,147,483,648 +2,147,483,647 (-231 to 231-1)
|
- Addressing modes: immediate, direct, indirect
‘Addressing modes’ refers to the allowable ways in which the processor instructions can refer to data. The 68000 has fourteen addressing modes and we looked at eleven of them through the course: two immediate modes, four direct modes and five indirect modes (the remaining three are a special case of the indirect modes). You select an appropriate addressing mode for a piece of data depending on how much you know about the data item itself when you’re writing the program.
Level of Knowledge of Data |
Kind of Addressing Mode |
Value can be known at assembly time |
Immediate Mode
(Immediate Values are sometimes called ‘Literals’) |
Location can be known at assembly time |
Direct Mode |
Location or value can be calculated at run time |
Indirect Mode |
- Immediate: Specify the operand as a byte, word or longword item. All sensible values are permitted of eight, 16 or 32 bits as appropriate. e.g: #21, #$12234 - $24
- Quick Immediate: some instructions and operands occur very frequently in the instruction execution stream, and some of these are speeded up by making the instruction shorter: MOVEQ, ADDQ and SUBQ for which:
- MOVEQ: allows eight bits to represent the immediate data. The destination operand must be a data register and operations are 32-bit long. E.g.: MOVEQ #0,D0
- ADDQ and SUBQ: allows three bits to represent the immediate data, mapped to the values 1 to 8. 8-,16-, or 32-bit operations are permitted and the destination is not restricted to a data register. E.g.: ADDQ.L #1,A0
- Data Register Direct: specify the data register on its own, no brackets or anything, E.g.: D0
- Address Register Direct: specify the address register on its own, E.g.: A2
- Absolute Memory Long: Memory Direct modes are used to specify where an operand is in memory. The address is represented in the instruction as a 32-bit item, e.g.: MOVE.L D0,$f0463047
- Memory Direct Short: To save space in an instruction, an abbreviated address can be stored in 16 bits. E.g.: MOVE.B #0,$2000
- Address Register Indirect: the address of an operand is found in an address register, rather than in the instruction. Address register indirect is indicated to the assembler by enclosing an address register in round parentheses; e.g: CLR (A0).
- Address Register Indirect with Post-Increment: The contents of the address register from which the operand address is derived are incremented by 1, 2 or 4 after the instruction has been executed depending on the operation size (byte, word o longword). E.g.:
MOVE.L D0-D7,(A7)+
- Address Register Indirect with Pre-Decrement: The contents of the address register are decremented by 1, 2 or 4 before the instruction is executed. E.g.:
MOVEM.L -(A7),D0-D7
- Address Register Indirect with Displacement: the effective address is calculated by adding the contents of an Address Register to a signed-extended 16-bit offset (or displacement). E.g:
MOVE.L 62(A7),A0
- Address Register Indirect with Index: the effective address is calculated by adding the contents of an address register to the contents of a general register, together with an 8-bit signed displacement. The general register can be a data or address register and is termed as index register: MOVE.L 4(A7,D7),D1
- Program flow control: unconditional branch and jump
Program flow can be non-sequential, i.e. an instruction could explicitly contain the address of its successor instruction. The 68000’s two unconditional branch/jump instructions are BRA and JMP.
The branch always instruction, BRA, forces a branch to the instruction whose address is indicated by the label following the BRA mnemonic. The unconditional branch is equivalent to the GOTO instruction in high-level languages. JMP is functionally equivalent to the branch, BRA. The difference between the branch and jump instruction is that a BRA instruction uses only relative addressing, whereas a JMP instruction may employ any standard addressing mode.
BRA <destination> ; branch always.
JMP <ea> ;jump.
- The Condition Code Register
The Condition Code register (CCR) is a special register that contains a set of flag bits (X, N, Z, V and C) which are set or clear according to the result of an arithmetic or logical operation. That is, the CCR provides a status report about the operation.
- N The negative bit. Set if the result is negative; cleared otherwise.
- Z The zero bit. Set if the result is zero; cleared otherwise.
- V The arithmetic overflow bit. Set if sign overflow occurred; cleared otherwise.
- C The carry/borrow bit. Set if arithmetic carry or borrow; cleared otherwise.
- X The extend bit. This is the same as the carry bit, but is only affected by a subset of the instructions that affect the carry bit: the ‘arithmetic’ instructions. X is set if arithmetic carry or borrow has occurred.
- Conditions and Conditional Branching
There are instructions that only have an effect if a particular condition holds true. In the 68000, conditions are: Boolean expressions that take the five bits of the Condition Code Register, True, false and the Boolean operators ‘and’ ,‘or’, ‘eor’ and ‘not’.
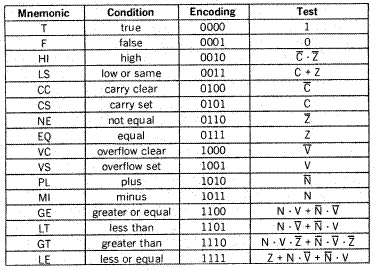
Conditions the 68000 recognises
- The 68000 provides the programmer with a toolkit containing instructions for the implementation of conditional structures: Bcc <label> Branch to label on condition cc true.
The condition cc, calculated into the CCR, is any one of the conditions the 68000 recognises, except T and F. The program execution ‘chooses’ between two courses of action by examining the condition ‘cc’ and associating one action with the outcome ‘True’ and another action with the other outcome, ‘False’.
- The DBcc instruction makes it easier to execute a loop a given number of times. The assembly language form is: DBcc Dn,<label> test condition cc, decrement Dn and branch to label if cc is false
Dn is a data register and <label> is a label used to specify a branch address. The label is assembled to a 16-bit signed displacement which permits a range of 32K bytes. If the result of the test is true, the branch is not taken and the next instruction in sequence is executed (i.e., exit the loop). If the specified condition is not true, the low-order 16-bits of register Dn are decremented by 1. In addition, if the resulting contents of Dn are equal to -1, the next instruction in sequence is executed. Any of the sixteen conditions recognised by the 68000 is valid, including T and F.
- High-level language constructs: while, if, for, etc.
High-level language |
Assembly language |
while [condition] {
[do stuff]
} |
loop Bcc do_stuff
next …
do_stuff …
BRA loop |
Do {
[do stuff]
}
while [condition] |
do_stuff …
Bcc do_stuff
next … |
for {[initial statement];[terminating condition];[each time operation]){
[do stuff]
} |
MOVE.L #final-1,Dn
do_stuff …
DBRA Dn,do_stuff
next … |
If ([condition]){
[do_then_stuff]}
else {[do_else_stuff]}
} |
Bcc do_then_stuf
do_else_stuff ….
next …
Do_then_stuff …
BRA next |
- Some complex 68000 instructions (op-codes with at least one extension word)
- Compare Instructions:
- CMP - sets the CCR as if the first operand had been subtracted from the second. The N-, Z-, V-, and C-bits are all updated and the X-bit remains unaffected. The destination operand must be a data register and the source operand may be specified by any of the 68000’s addressing modes: e.g.: CMP.L D0,D1 evaluates [D1(0:31)] – [D0(0:31)]
- TST - reads the operand, compares it with zero, and sets the bits of the CCR accordingly. E.g.: TST D3 has a similar effect to CMP #0,D3.
- Bit Test Instructions:
- BTST: Bit TeST tests a bit of an operand. If the test bit is zero, the Z-bit of the CCR is set, else the Z-bit is cleared. A bit test does not affect the value of the operand under test in any way. The location of the bit to be tested is specified by a constant, or as the contents of a data register. For example, BTST #3,(A0) tests bit 3 of the byte in memory pointed at by A0. BTST D0,(A0) tests the bit in the byte pointed at by A0 whose bit-number is in D0.
- BSET: Bit Test and SET causes the Z-bit of the CCR to be set if the specified bit of an operand is zero, and then forces it to be set to one. eg: BTSET #4,D0.
- BCLR: Bit and CLeaR works exactly like BSET, except that the specified bit is cleared after it has been tested.
- BCHG: Bit test and CHanGe causes the value of the specified bit to be tested and then inverts its state.
- Logical Operations:
- The NOT operation simply inverts the bits of an operand.
- The AND operation is applied to a source and destination operand. Each bit of the source operand is ANDed with the corresponding bit of the destination operand and the result is stored in the destination operand.
- The OR operation sets one or more bits to 1.
- The EOR operation is use to toggle one or more bits. EORing a bit with 0 has no effect, and EORing it with 1 inverts it.
- Shift Operations:
- LSL and LSR: in a logical shift all the bits are moved left or right and zero enters at the input of the shifter. A logical shift left is indicated by LSL and a shift right by LSR. The bit shifted out of one end of the register is placed in the carry flag of the CCR and also the X flag.
- Arithmetic shift operations, ASL and ASR, behave in the same way as logical shift operations, except that the overflow bit is set if the most-significant bit of the operand is changed at any time during the shift operation (i.e., if the number changes sign).
- An arithmetic shift right, ASR, causes the most-significant bit, the sign-bit, to be propagated right and, therefore, preserves the correct sign of a two's complement value.
- In a circular shift the bit shifted out is moved to the position of the bit shifted in. The bits are shifted left by ROL, rotate left, and right by ROR, rotate right.
- The rotate through extend instructions, ROXL and ROXR, behave rather like the ROL/ROR pair, except that the rotate includes the X-bit.
- Subroutines: mechanisms and parameter passing
- Functions, methods and procedures are mostly implemented at assembly language level as ‘subroutines’. A subroutine is simply a section of code designed to be called (branched or jumped to) from many places. The BSR and JSR instructions store the address of the next sequential instruction just before they branch or jump to the subroutine. They store the ‘return address’ in The Stack. A subroutine is called by executing the instruction BSR <label> or JSR <label>, for Branch to SubRoutine and Jump to SubRoutine. The difference between BSR and JSR is that BSR uses a relative address and JSR an absolute address. The programmer simply supplies the label of the subroutine and the assembler automatically calculates the appropriate relative or absolute address. The range of branching with BSR is -32K bytes to +32K bytes from the present instruction.
- The stack is a fundamental data structure that makes possible to call subroutines in both high-level and low-level languages with little difficulty. The stack is a last in, first out (LIFO) queue with a single end, where items are always added or removed. When an item is added to the stack it is said to be pushed on to the stack, and when an item is removed from the stack it is said to be pulled (or popped) off the stack. The 68000 stack is located in a region of the main memory and address register A7 is used as system stack pointer to point to the top of the stack.
- Most programmers would employ a MOVEM instruction to save the contents of registers on the stack before they are used by a subroutine, and then restore them immediately before executing a return from subroutine. MOVEM stands for move multiple; it transfers the contents of a group of registers to or from memory with a single instruction. E.g.: MOVEM.L D0-D7/A0-A6,-(A7) pushes all the data registers and address registers A0 to A6 onto the system stack. MOVEM.L (A7)+,D0-D7/A0-A6 has the reverse effect of pulling the registers off the stack.
- Subroutines and Parameter Passing:
- Address and data registers provide a handy vehicle to transfer the information between a subroutine and its calling program. Unfortunately, you can't use registers to transfer large quantities of data to and from subroutines, owing to the limited number of registers.
- An ideal way of passing information between a subroutine and its calling program is via the stack. The parameters are then pushed on the stack immediately before the subroutine call. On entering the subroutine, the parameters can be retrieved from the stack by making a copy of it in another address register to avoid moving the system stack pointer A7 below the top-of-stack. By using the stack to pass parameters to a subroutine, the subroutine may be interrupted and then used by the interrupting program without the parameters being corrupted. As data is stored on the stack, it is not overwritten when subroutine is interrupted because new data is added at the top of the stack, and then removed after the interrupt has been serviced.
- Parameters can be passed by value or by reference. Passing a parameter by value consists of moving a copy of a parameter to the subroutine by pushing its value on the stack. With this mechanism, changing the parameter’s value within the subroutine does not change its value in the calling program. You can also pass a parameter to a subroutine by reference. The PEA (Push Effective Address) instruction can be used to push an address in the stack; e.g.: the operation PEA PQR pushes the address PQR on the stack. This instruction is equivalent to: MOVE.L #PQR,-(A7).
In practice, you would pass parameter that are not changed in the subroutine by value, and only pass parameters that are to be changed by reference.
- What is a ‘well behaved’ subroutine?
Subroutines run in the same context as their callers—same register values, memory locations etc. Thus, subroutines are part of the caller’s process. They are not independent of the caller. Care must be taken to ensure that subroutines do not damage the context of their callers. In a kind of shorthand, use of subroutines must be, eh, ‘ecological’ with respect to the environment:
- Easy To Use: Subroutines should be easy to understand.. Subroutines should do exactly and only what is specified and absolutely no more. Extra features frequently have unintended consequences. The scheme for passing parameters should be simple and neat.
- Register Use: if a subroutine uses a register as a local variable, its contents must be saved before use, and then restored afterwards. In that way, the register’s contents are preserved for the caller.
- Parameter Passing: Use registers to pass parameters to and from a subroutine, where possible. Use the stack if necessary. Make sure all uses of the stack are ‘balanced,’ i.e. pushes=pops.
- Memory Use: A subroutine should avoid using fixed memory locations for anything. If a subroutine needs memory space, take it from the stack, if possible.
- Principles of input/output: polling
I/O interfaces mediate logically and physically between part of the outside world and the world on the computer. The actual input/output strategy defines how I/O operations are performed.
- The 68000 employs memory-mapped I/O in which I/O ports are located within the processor’s memory space. Then the actual input/output strategy defines how I/O operations are performed. Programmed I/O normally takes place when an instruction in a program initiates the data transfer; the processor simply reads from or writes to the appropriate memory-mapped I/O port whenever it wishes to perform I/O. Associated with programmed I/O is the polling loop, in which an I/O port is continually tested until it is ready to perform a data transfer.
- The pooling loop is essential in a programmed I/O transfer since most peripherals connected to an I/O port are relatively slow devices, and transferring data to then at the CPU’s rate would result in almost all data being lost. Some interfaces are able to deal with high-speed data because they store data in a buffer. They can’t, however, deal with a continuous stream of data at high speeds because the data buffer quickly fills up and then overflows. A solution to the problem of dealing with such a mismatch in speed between computer and peripheral is found by asking the peripheral if it’s ready to receive or transmit data, and not sending data to it until it is ready to receive it. That is we introduce a form of software handshaking procedure between the peripheral and the interface.
- For example, a typical slow printer operates at 30 characters per second or approximately 1 character per 33000 μs. Because the polling loop takes about 3μs, the loop is executed 11000 times per character.
- Exceptions and exception handling
- The 68000 has extra hardware to recognise and to deal with exceptional situations, such as errors, hardware notifications and elective exceptions. At the start of every exception, the following steps are performed by the hardware:
- If exception is not RESET make internal copy of the Status Register.
- Turn off T (Trace) bit, turn on S (Supervisor) bit of the supervisor byte of the SR. If the exception is RESET, then set I2I1I0 of SR to 111.
- If exception is not RESET, Set priority equal to priority of interrupt being acknowledged,save current PC and internal copy of SR on stack.
- From the source of the exception, and possibly other information, determine the exception’s vector number.
- Take the longword at the address equal to 4*Exception Vector Number, and use it as the address of the exception handler - i.e. jump to the address given by this longword. (In the case of a RESET exception, two longwords are used: the first is loaded into A7 as the initial Stack Pointer value; the second longword is the start address of the reset exception handler).
- Internally generated exceptions: Elective (E.g. TRAPs; TRACE), Error detection exceptions (Divide by Zero, CHK, Address Error), etc.
- External generated: E.g. RESET, HALT, Bus Error (BERR), External Interrupts.
- Supervisor and user mode
- Programs in the 68000 can run in two levels of privilege. If you examine the Status Register, the S bit specifies the level of privilege of the program currently: if S=1, then the machine is in the supervisor mode, otherwise it is in the user mode.
SYSTEM BYTE |
USER BYTE (CCR) |
T |
_ |
S |
_ |
_ |
I2 |
I1 |
I0 |
_ |
_ |
_ |
X |
N |
Z |
V |
C |
The 68000 Status register
- In the supervisor mode, all the system's resources: instructions, registers, memory locations, etc... are available to be used. In user mode, however, only a subset of the resources is available – the remainder are privileged. If a user-level program attempts to use a privileged resource, then a privilege violation exception will occur.
- All instructions that allow a program to change the level of privilege are themselves privileged, so a program cannot promote itself. Also, any instruction which affects the overall state of the computer is privileged (e.g. HALT, RESET). Similarly, if a user-level program tries to access memory that it is not allowed to, then a bus-error exception will occur (if the hardware is properly designed), preventing it from getting access to, and possibly damaging, the resources of another program.
- Interrupts and interrupt handlers
- The purpose of external Interrupts is to allow outside-world events to be signalled to the processor, to generate exceptions. The resulting exception handlers (called interrupt handlers) deal with the interrupt (i.e. “service” the interrupt):
- Three bits in the SR: I2I1I0 represent the priority of the currently-running program.
- Three Interrupt Priority Level (IPL) lines on the system bus (more of which later) - IPL2’, IPL1’, IPL0’ - are used by peripherals to signal interrupt requests.
- An Interrupt Acknowledge Cycle is a special bus cycle used by the processor to get a vector number for the interrupt request. Peripheral Devices need some facilities to permit interrupts. They must be able to generate interrupt requests and respond to an interrupt acknowledge cycle. If the peripheral cannot fully respond, then it must be able to signal that it. If the peripheral is unable to provide a vector number, an AutoVector is used instead.
- When an interrupt request is recognised, the normal exception handling sequence is entered, with some specialisations:
- Make internal copy of the SR.
- Turn off T bit, turn on S bit. Set priority equal to priority of interrupt being acknowledged.
- Save current PC and internal copy of SR on stack.
- Use an Interrupt Acknowledge Cycle to get the exception’s vector number.
- Take the longword at the address equal to 4*Exception Vector Number, and use it as the address of the exception handler - i.e. jump to the address given by this longword.
- Make the interrupt handler’s priority equal to the interrupt to ensure another interrupt of equal or lower priority can not interrupt the handler.
- Interrupt-driven I/O vs polling: Interrupt-driven I/O requires a more complex program than programmed I/O because the information transfer takes place when the data is available rather than when the programmer wants or expects it. Because the processor executes an interrupt handling routine only when a peripheral requests an I/O transaction, interrupt-driven I/O is very much more efficient than polled I/O.
- Producer consumer organisation
- Using interrupts to do Input/Output (I/O) has a very profound effect on the organisation of programs. Interrupts generally occur as a result of something happening outside the realm of the program, so must be handled specially.
- For instance, a character will arrive from a keyboard and generate an interrupt when the user has pressed the key, not necessarily when the program wants to receive the character. The program may indeed be waiting for the character, or the program may be doing something else and may not need the character until later.
- Similarly, a program may have a large number of characters to output, while the UART will be only able to handle one character at a time, and slowly too. At the other end, the UART may generate ant Interrupt to signal that it is ready to accept a new character for transmission. The program may already have a character to send, or it may not [yet] have one.
- To deal with these issues, we need to think differently about I/O. It becomes useful to think of the interrupt handler and its program as separate program entities ("processes") that interact through some shared resources. If one is a producer and the other is a consumer, then a shared queue or even some shared memory location could be used.
- Queues and buffers
- A keyboard or an output device might be connected to its consumer or producer via a queue.
Using a queue, for instance, the incoming character interrupt handler could place the character in a queue. So characters would not necessarily be lost if they were received before they were needed. The program requiring the character could look in the queue instead of looking at the UART.
- Similarly, the program needing to output characters could put them in an output queue, and then go on about its own business. The output interrupt handler could look into the queue to find the next character to send.
- Introduction to the system bus
- Signal summary:
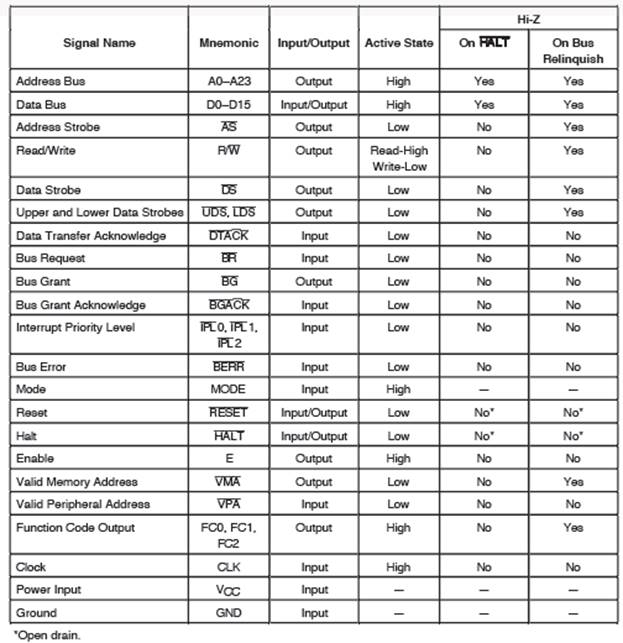
- The main aspects of Bus Cycles are:
- The Address and Data Buses are concerned with words, not bytes.
- Address Strobe (AS’) validates the address bus and the function codes
- Upper Data Strobe (UDS’) validates the ‘upper’ byte of the data bus – D15 to D8. This is the even-addressed byte in the word addressed by the Address Bus.
- Lower Data Strobe (LDS’) validates the ‘lower’ byte of the Data Bus – D7 to D0. This is the odd-addressed byte in the word addressed by the Address Bus.
During a read cycle, the processor receives either one or two bytes of data from the memory or from a peripheral device. If the instruction specifies a word or long-word operation, the processor reads both upper and lower bytes simultaneously by asserting both upper and lower data strobes. When the instruction specifies byte operation, the processor uses the internal A0 bit to determine which byte to read and issues the appropriate data strobe.
When A0 equals zero, the upper data strobe is issued; when A0 equals one, the lower data strobe is issued. When the data is received, the processor internally positions the byte appropriately.
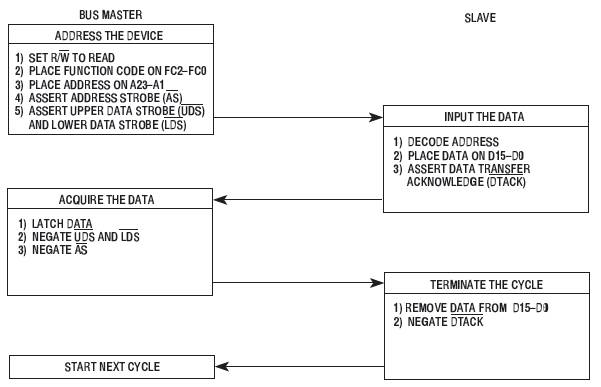
Word Read-Cycle Flowchart
During a write cycle, the processor sends bytes of data to the memory or peripheral device. If the instruction specifies a word operation, the processor issues both UDS and LDS and writes both bytes. When the instruction specifies a byte operation, the processor uses the internal A0 bit to determine which byte to write and issues the appropriate data strobe. When the A0 bit equals zero, UDS is asserted; when the A0 bit equals one, LDS is asserted.
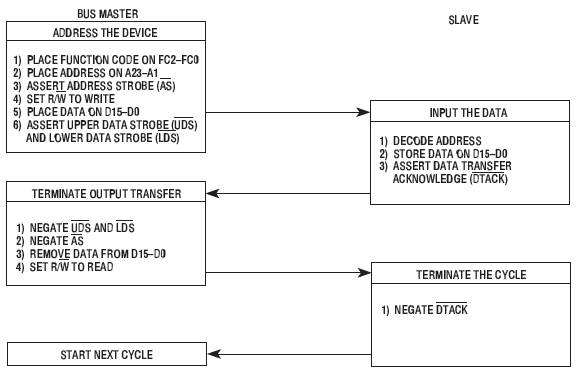
Word Write-Cycle Flowchart
- Interrupt Acknowledge Cycle:
An interrupt acknowledge cycle places the level of the interrupt being acknowledged on address bits A3–A1 and drives all other address lines high. The interrupt acknowledge cycle reads a vector number when the interrupting device places a vector number on the data bus and asserts DTACK to acknowledge the cycle. The timing diagrams for an interrupt acknowledge cycle is shown in Figure 29.4. Alternately, the interrupt acknowledge cycle can be autovectored. The interrupt acknowledge cycle is the same, except the interrupting device asserts VPA instead of DTACK. For an autovectored interrupt, the vector number used is $18 plus the interrupt level. This is generated internally by the microprocessor when VPA (or AVEC) is asserted on an interrupt acknowledge cycle. DTACK and VPA (AVEC) should never be simultaneously asserted.
- Instruction execution
- The Von Newman architecture model of a computer states that the CPU is responsible for reading instructions from the memory system and executing them. The CPU operates by following the so called fletch-decode-execute cycle:
- Fetch the operation word
- Decode the operation word
- Fetch the rest of the instruction—the extension words
- Fetch any off-processor operands
- Perform the operation itself.
The cycle repeats after the CPU takes the time to put away results to off-processor locations.
- Fetching an instruction begins with the contents of the Program Counter being moved to the Memory Address Register ([MAR] <- [PC]). The MAR is now pointing at the next instruction to be executed. Once the PC has done its job, it is automatically incremented to point the next instruction in sequence. After the increment, the PC points at the next instruction while the current instruction is being executed.
- The next step is to read the contents of the memory location pointed at by the MAR. The data read from memory is first deposited in a temporary holding register, the Memory Buffer Register ([MBR]<-[MAR]).
- In the final step of the fletch cycle the contents of the MBR are copied the Instruction Register ([IR]<-[MBR]). The IR holds the instruction while it is decoded by the Control Unit. One field of the IR contains the operation code (op-code) that tells the CPU what operation is to be carried out. A second field, called the operand field, contains the address of the data to be used by the instruction.
- The fletch phase is followed by an execution phase in which the Control Unit generates all signals necessary to execute the instruction. The CU controls all parts of the CPU including all programmable register set and Arithmetic and Logic Unit.
- A path between the CCR and the CU is used by the CU to decide whether to continue with the next instruction in series, or to jump to the address field specified by the branch field of a conditional instruction.
- Instruction timing
- You can get a good estimate of an instruction execution time by calculating the number of bus transactions required to fetch the instruction and its extension words, fetch the off-processor operands and put away the off-processor results.
- The bus can transfer one word (or part) in each transaction (a bus cycle). On the 8MHz 68000, a transaction takes 0.5μS.
- These estimates assume that bus transactions always take a fixed amount of time. However, an instruction cache could shorten bus transactions fetching an instruction and data cache could do the same for fetching or putting away data.
- So, these would be worst-case estimates for a machine with a cache. But the 68000 doesn’t have a cache. The 68000 has a one-instruction look-ahead facility:
- While the current instruction is being executed, the operation word of the next one is being fetched.
- Any operation that takes less than one bus transaction is ‘invisible’ and doesn’t add any overall time to instruction execution (as per our assumption).
- A branch requires the pre-fetched operation word to be discarded—penalty: one half of a bus transaction.
- Multiply and divide instructions take way in excess on one transaction.